
목표 : 순환 신경망을 만들어 리뷰 데이터 셋에 적용해서 리뷰를 긍정과 부정으로 분류하기
핵심 키워드 : 말뭉치, 토큰, 원 - 핫 인코딩, 단어 임베딩
핵심 패키지와 함수 : pad_sequences(), to_categorical(), SimpleRNN, Embedding
데이터셋 : IMDB 데이터 셋
IMDB 리뷰 데이터셋
- imdb.com 에서 수집한 리뷰를 감상평에 따라 '긍정' 과 '부정' 으로 분류해 놓은 데이터 셋
- 총 50,000개의 샘플
- 훈련:테스트 => 25,000개:25,000개

NLP 와 말뭉치(corpus)
자연어처리(natural language processing, NLP) 는 컴퓨터를 사용해 인간의 언어를 처리하는 분야
ex ) 음성인식, 기계번역, 감성 분석, 주제 분석, 챗봇
자연어 처리 분야에서의 훈련 데이터를 말뭉치라고 부른다.
IMDB 리뷰 데이터 셋이 하나의 말뭉치이다.
토큰 (Token)
텍스트 -> 숫자데이터로 변환해야 한다.
일반적으로 분리된 단어에 고유한 정수를 부여하는 것
He follows the cat. He loves the cat
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
10 11 12 13 10 14 12 13
하나의 샘플은 여러개의 토큰으로 이루어져 있고, '1개의 토큰'이 '하나의 타임 스텝'에 해당된다.
토큰에 할당되는 정수중 특별한 용도로 예약되어 있는 경우가 있다.
ex)
0 - 패딩
1 - 문장의 시작
2 - 어휘 사전에 없는 토큰 (OOV: out of Vocabulary)
어휘사전 : 훈련세트에서 고유한 단어를 뽑아 만든 목록
keras에서 읽어오는 IMDB 데이터셋은 이미 토큰화가 되어있다
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os, ison, re, random
import tensorflow as tf
form tensorflow import keras
def set_seed(seed = 42):
tf.keras.utils.set_random_seed(seed)
set_seed(42)
IMDB 데이터 준비
form keras.datasets import imdb
num_words = 10000 # 단어사전 크기
(train_input,train_target), (test_input,test_target)=imdb.load_data(num_words=num_words)전체 데이터 셋에서 가장 자주 등장하는 단어 num_words = 만큼만 사용지정
num_words= 를 지정하지 않으면 88584 만큼 단어가 로딩 되어 인덱스 크기가 매우 커져 이렇게 진행
Data 확인
print(train_input.shape, test_input.shape)
# (25000,) (25000,)이미 토큰화가 되었는데 배열이 1차원으로 나왔다.
train_input.dtype
# dtype('O') <-- 데이터원소가 Python Object 라는 뜻. (리스트!)
# 리뷰 텍스트의 list 길이가 제각각입니다.
# 따라서 고정크기의 2차원 배열에 담기 보다는
# 리뷰마다 별도의 파이썬 리스트로 담아서 메모리를 효율적으로 사용하는 겁니다
print(len(train_input[0])) # train 데이터의 첫번째 리뷰의 토큰 개수
print(len(train_input[1])) # train 데이터의 두번째 리뷰의 토큰 개수
# 218
# 189
# ↑ 각 리뷰마다 길이가 다릅니다.
# 여기선 하나의 리뷰가 하나의 샘플이 된다.
print(train_input[0])
# [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468,...]
# ↑ TF 의 IMDB 리뷰 데이터는 이미 정수로 변환되어 있다.
# 앞서 num_words=10000 으로 지정했기 때문에 어휘 사전에는 10000개의 단어만 들어가 있습니다.
# 단어 사전에 없는 단어(OOV)는 모두 2로 표시되어 나타납니다
# ※imdb_load_data() 함수는 num_words 개의 단어를 '많이 등장한 횟수순' 으로 고릅니다.
Target 확인
print(train_target[:20])
# ↓ 해결할 문제는 리뷰가 '긍정(1)'인지 '부정(0)'인지 판단하는 것
# 이진(binary)분류 문제다. sigmoid 사용
# [1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]
IMDB 데이터 확인하기
다음과 같은 순서로 데이터 확인은 가능하다
1. 단어인덱스 가져오기
단어 인덱스를 (단어 -> 인덱스)에서 (인덱스 -> 단어)로 변환
인덱스가 3부터 시작하므로 인덱스 오프셋을 적용
2. 리뷰를 실제 단어로 변환해서 출력하기
주의!
직전의 토큰화 하여 정수 인덱싱된 입력데이터(문장)는 단어가 인덱스 3부터 시작
지금의 단어인덱스는 0-base 인덱스 사용 (문장의 인덱스와 인덱스 오프셋 차이 +3)
단어인덱스 (단어사전)
# 1. 단어 인덱스 가져오기
word_index = imdb.get_word_index()
print(type(word_index), len(word_index)) #dict, 88584개
print(word_index)
word_index['woods'] # 특정 단어 -> 사전 인덱스
# 단어 인덱스를 {단어:인덱스} 에서 {인덱스:단어} 로 변환
reverse_word_index = {value:key for key,value in word_index.items()}
print(reverse_word_index)
# 단어인덱스 1부터 시작하여 88584개의 단어가 있다.
reverse_word_index[88584]
IMDB 데이터셋의 문장 인덱스는 3부터 시작하므로 인덱스 오프셋을 적용
IMDB 데이터셋에서 인덱스 오프셋이 3인 이유는 다음과 같은 특별한 토큰들을 예약해 두기 위해서입니다:
0: 패딩 토큰 (padding token)
1: 시작 토큰 (start token)
2: 알 수 없는 단어 (unknown token, OOV)
# 정수 인코딩된 문장을 단어로 구성된 문장으로 디코딩
def decode_review(encoded_review):
return ' '.join([reverse_word_index.get(i -3,'?') for i in encoded_review])
i 번째 리뷰를 실제 단어로 변환해서 출력하기
i = 1
decoded_review = decode_review(train_input[i])
print(train_input[i]) # 토큰 인덱스 값
print(decoded_review) # decode 된 단어
print(train_target[i])
Train data 에서 Validation data 세트 분리하기
# train 와 validation 을 분리하는 이유 -> 나중에 overfit 이 잘 제어되는지 확인하기 위함
# 원래 train 데이터가 25,000 개였고 20%를 검증(val) 세트로 떼어 놓으면
# train 데이터는 20,000 개로 줄어들거다
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2,
random_state=42)
train_input.shape, val_input.shape
# ((20000,), (5000,))
패딩
자연어 처리를 하다보면 각 문장(또는 문서)은 서로 길이가 다를 수 있습니다.
그런데 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고,
한꺼번에 묶어서 처리할 수 있습니다.
다시 말해 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요!.
적절한 길이의 padding 값 찾기
# 문장의 길이(들)
lengths = np.array([len(x) for x in train_input])
print(np.min(lengths), np.max(lengths), np.mean(lengths), np.median(lengths))
#11 1854 239.00925 178.0
# ↑ [관찰]
# 평균 단어 개수가 239개. 중간값 178 인것으로 보아 이 리뷰 데이터는 한쪽에 치우진 분포
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()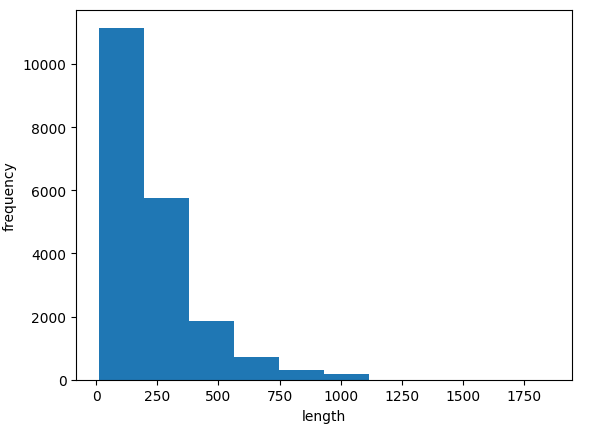
한쪽으로 치우졌다. 대부분의 리뷰 길이는 300 미만이다.
평균이 중간값보다 높은 이유는 오른쪽 끝에 아주 큰 데이터가 있기 때문이다.
패딩 pad_sequences()
리뷰는 대부분 짧다. 중간값보다 훨씬 짧은 100개의 단어만 사용해보자.
길이 100보다 긴 리뷰는 잘릴 것이고
길이 100보다 작은 리뷰는 '패딩' 토큰이 채워질거다.
일반적으로 패딩 토큰은 '0' 을 사용
from keras.preprocessing.sequence import pad_sequences
# padding 전. 두개 샘플 확인
len(train_input[0]), len(train_input[5])
# (259, 96)
max_len = 100
train_seq = pad_sequences(
sequences =train_input,
maxlen= max_len,
)
# padding 후!
len(train_seq[0]), len(train_seq[5])
# (100, 100)
truncating=
maxlen= 보다 길이가 큰 시퀀스에 대해
- 'pre' : 앞부분 자름
- 'post' : 뒷부분 자름
padding=
maxlen= 보다 작은 길이의 시퀀스에 대해
- 'pre' : 앞쪽에 패딩토큰 추가 (디폴트)
- 'post' : 뒤쪽에 패딩토큰 추가
# validation 세트도 길이 max_len으로 맞추어 놓음
val_seq = pad_sequences(val_input,maxlen=max_len)
val_seq.shape
순환 신경망 만들기 SimpleRNN
# keras 는 여러 순환층 클래스 제공
# 그중에서 가장 간단한것이 SimpleRNN 클래스
set_seed(42)
model = keras.Sequential() # keras 에서 모델 쌓기 위해 제공하는 방법
# 입력 shape(100, 10000) <- one-hot encoding 결과를 입력
# 입력차원 2차원
# (문장 최대길이, 10000개의 어휘)
model.add(keras.layers.Input(shape=(max_len, num_words)))
model.add(keras.layers.SimpleRNN(units=8))
# 출력 shape(8,)
# IMDB 리뷰문제. 이진분류 문제
model.add(keras.layers.Dense(1, activation='sigmoid'))
# 출력 shape(1,)
one-hot encoding
단어 토큰값(정숫값) 은 산술 연산과는 관련 없는 데이터다.. (수치형 데이터가 아니다)
즉, 수치형데이터가 아니라 '분류형' 이다.
이를 고유하게 표현하는 방법으로 one-hot encoding 사용
# 첫문장 seq 확인
train_seq[0]
"""
array([ 10, 4, 20, 9, 2, 364, 352, 5, 45, 6, 2, 2, 33,
269, 8, 2, 142, 2, 5, 2, 17, 73, 17, 204, 5, 2,
19, 55, 2, 2, 92, 66, 104, 14, 20, 93, 76, 2, 151,
33, 4, 58, 12, 188, 2, 151, 12, 215, 69, 224, 142, 73,
237, 6, 2, 7, 2, 2, 188, 2, 103, 14, 31, 10, 10,
451, 7, 2, 5, 2, 80, 91, 2, 30, 2, 34, 14, 20,
151, 50, 26, 131, 49, 2, 84, 46, 50, 37, 80, 79, 6,
2, 46, 7, 14, 20, 10, 10, 470, 158], dtype=int32)
"""↓ 예를들면 위 첫문장 seq 의 첫번째 토큰 10 을 one-hot encoding 으로 바꾸면

# 하나의 토큰을 0 과 1의 배열로 표현
# 그 배열에는 한개만 '1' 이고 나머지는 '0'
# 배열의 크기를 10000. <- imdb.load_data() 에서 10000개의 단어만 사용
# 고유한 단어(토큰)는 모두 10000개
# 훈련데이터에 포함된 정수값의 범위는 0(패딩토큰) ~ 9999
# 따라서 이 범위를 one-hot encoding 으로 표현하면 '토큰 하나'가 '길이 10000의 배열'로 표현된다.to_categorical()
# one_hot encoding 전
print(train_seq.shape)
# (20000, 100)
# one-hot encoding
train_oh = keras.utils.to_categorical(train_seq)
# one-hot encoding 후 shape
print(train_oh.shape)
# ↓ 첫번째 토큰 10이 One-hot encoding 으로 변환된 모습
print(train_oh[0][0])
# (20000, 100, 10000)
그래서! Input shape 는 (100, 10000) 이다
(sequence 길이, 단어표현길이)
↑ ↑
패딩 단어사전
model.add(keras.layers.Input(shape=(100, 10000))) 인 것이다!
# 이제 검증에 사용된 validation 세트도 one-hot encoding 으로 준비해두자
val_oh = keras.utils.to_categorical(val_seq)
모델 파라미터 계산
model.summary()
"""
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ simple_rnn (SimpleRNN) │ (None, 8) │ 80,072 │
입력 shape (100, 10000)
parameter 개수
1. 입력 parameter
10000 * 8 = 80000
2. 은닉상태 paramerter
8 * 8 = 64
3. 절편 bias
8
1. + 2. + 3. = 80072
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 1) │ 9 │
입력 parameter
8 * 1 = 8
절편
1
└─────────────────────────────────┴────────────────────────┴───────────────┘
"""
순환 신경망 학습하기
set_seed(42)
# optimizer , compile
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4) # learning-rate : 0.0001
model.compile(optimizer=rmsprop,
loss='binary_crossentropy', # one-hot encoding 되어 있는 '이진 분류' 문제에선.
metrics=['accuracy'])
# 체크포인트 callback, 가장 학습결과가 좋은 모델을 저장함
checkpoint_cb = keras.callbacks.ModelCheckpoint(
os.path.join(base_path, 'best-simplernn-model.keras'),
save_best_only=True)
# 조기종료
# 더이상 학습상태가 낳아지지 않으면 바로 epoch 종료.
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history1 = model.fit(train_oh, train_target,
epochs=100, batch_size=32, # 100번의 에포크
validation_data=(val_oh, val_target),
callbacks=[
checkpoint_cb, # check point
early_stopping_cb, # 조기 종료
])
plt.plot(history1.history['loss']) # training loss
plt.plot(history1.history['val_loss']) # validation loss
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
ont-hot encoding 의 문제점!
- 입력데이터의 용량이 너무 커진다!
결국... 훈련데이터가, 사전의 크기가 커질수록 문제가 될것이다.
'AI > ML' 카테고리의 다른 글
| LSTM(1) (0) | 2026.04.14 |
|---|---|
| 순환 신경망으로 IMDB 리뷰 분류하기 - Word embedding (단어 임베딩) (0) | 2026.04.13 |
| RNN : 순서가 있는 데이터를 처리하는 신경망 (0) | 2026.04.02 |
| CNN으로 MNIST 손글씨 분류하기 (TensorFlow) (0) | 2026.03.29 |
| CNN : Convolutional Neural Network (0) | 2026.03.29 |